Attention is all you need
한 줄 요약
Transformer 구조에 대해 알아본다.
Introduction
이전까지 주로 사용해왔던 모델 - RNN, LSTM, GRU- 은 $h_{t}$ 를 계산해야 $h_{t+1}$ 을 계산할 수 있게끔 설계되었다. 이러한 구조는 parallel 하게 계산하기 힘들고 input 에 따라 실행시간이 달라지는 문제 등이 있다. 이 논문에서는 attention 을 극한으로 이용해서 시간에 종속되지 않는 neural network architecture; tranformer 를 제안한다.
Architecture
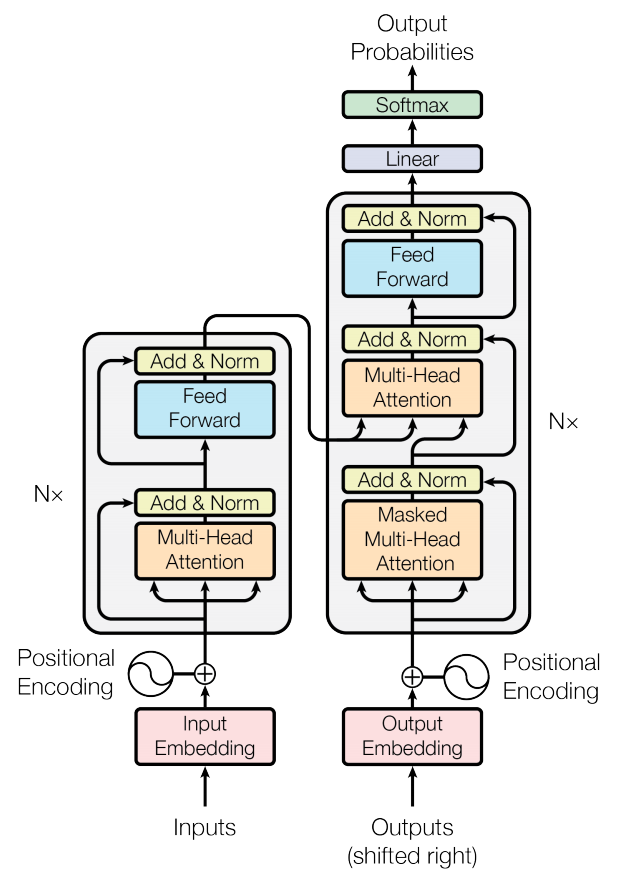
기본 구조는 다음과 같다. Decoder 의 input 으로 shifted right 되어 들어가는데, 그 이유는 바로 복사되어 output 이 되는걸 막기 위해서다. 이렇게 함으로써 i 번째 위치의 단어는 i-1,..,1 번째 위치만 보고 추론하게 된다. training 할 때, 처음에는 outputs 에 첫 element 만 start of sentence 토큰을 넣고 inference 하고 그 뒤로 나온 단어를 두 번째 element 로 넣고 inference 하는 식으로 outputs 을 구성해 가면서 inference 한다.
class Transformer(nn.Module):
def __init__(self, params):
super(Transformer, self).__init__()
self.encoder = Encoder(params)
self.decoder = Decoder(params)
def forward(self, source, target):
# source = [batch size, source length]
# target = [batch size, target length]
encoder_output = self.encoder(source) # [batch size, source length, hidden dim]
output, attn_map = self.decoder(target, source, encoder_output) # [batch size, target length, output dim]
return output, attn_map
이제 이 그림에 나오는 것들을 하나씩 살펴보겠다.
Encoder
6 개의 같은 layer 로 구성되어 있고 각 layer 는 2개의 sublayer 로 구성된다. 하나는 multi-head self-attention mechanism 이고 나머지 하나는 potision wise fully connected feed-forward network 이다. 각 sublayer 는 residual block 이 적용된다. 즉, norm(x+sublayer(x)) 의 형태로 sublayer 의 output 이 출력된다. 이를 위해 embedding 을 포함하여 sublayer 의 output dimension 은 512 로 고정한다.
class EncoderLayer(nn.Module):
def __init__(self, params):
super(EncoderLayer, self).__init__()
self.layer_norm = nn.LayerNorm(params.hidden_dim, eps=1e-6)
self.self_attention = MultiHeadAttention(params)
self.position_wise_ffn = PositionWiseFeedForward(params)
def forward(self, source, source_mask):
# source = [batch size, source length, hidden dim]
# source_mask = [batch size, source length, source length]
# Original Implementation: LayerNorm(x + SubLayer(x)) -> Updated Implementation: x + SubLayer(LayerNorm(x))
normalized_source = self.layer_norm(source)
output = source + self.self_attention(normalized_source, normalized_source, normalized_source, source_mask)[0]
normalized_output = self.layer_norm(output)
output = output + self.position_wise_ffn(normalized_output)
# output = [batch size, source length, hidden dim]
return output
Decoder
Encoder 와 구조는 비슷한데, encoder 의 output에 대해 multi-head attetion 을 취하는 sub-layer 가 하나 추가된 형태로 layer 을 구성하고 그것이 6개 있다. 하나의 multi-head attention 은 masking 을 취해서 변형시키는데, 이 변형으로 이전 위치의 값이 적용되는걸 막는다. 따라서 i 위치에 대한 예측이 i 이전의 값들을 보고 예측한다는 것을 보장한다.
class DecoderLayer(nn.Module):
def __init__(self, params):
super(DecoderLayer, self).__init__()
self.layer_norm = nn.LayerNorm(params.hidden_dim, eps=1e-6)
self.self_attention = MultiHeadAttention(params)
self.encoder_attention = MultiHeadAttention(params)
self.position_wise_ffn = PositionWiseFeedForward(params)
def forward(self, target, encoder_output, target_mask, dec_enc_mask):
# target = [batch size, target length, hidden dim]
# encoder_output = [batch size, source length, hidden dim]
# target_mask = [batch size, target length, target length]
# dec_enc_mask = [batch size, target length, source length]
# Original Implementation: LayerNorm(x + SubLayer(x)) -> Updated Implementation: x + SubLayer(LayerNorm(x))
norm_target = self.layer_norm(target)
output = target + self.self_attention(norm_target, norm_target, norm_target, target_mask)[0]
# In Decoder stack, query is the output from below layer and key & value are the output from the Encoder
norm_output = self.layer_norm(output)
sub_layer, attn_map = self.encoder_attention(norm_output, encoder_output, encoder_output, dec_enc_mask)
output = output + sub_layer
norm_output = self.layer_norm(output)
output = output + self.position_wise_ffn(norm_output)
# output = [batch size, target length, hidden dim]
return output, attn_map
이제부터 구체적인 sub-layer 들과 구조에 대해 서술하겠다.
Embeddings & Softmax
구체적으로 어떤 임베딩을 썼는지는 나와있지 않지만 단순한 word 단위 임베딩을 사용한 것 같다. Language model 에서 weight tying 쓰듯이, input 과 output 에서 쓰이는 embeeding layers 와 pre-softmax linear transformaction matrix 에서 동일한 weight matrix 를 사용한다. 또, embedding layers 에 $\sqrt {d_{model}}$ 를 곱해 scale을 바꿔준다.
=> encoder 와 decoder 의 embedding 을 같은 weight matrix 로 사용하면 사전적 의미는 유사하지만 뉘앙스가 다른 단어의 경우를 잘 처리하지 못할 것 같은데 왜 잘되는걸까?
Positional encoding
transformer 방식에선 위치 정보가 없기 때문에 embedding vector 에 위치 정보를 넣어줘야 한다. 임베딩과 같은 차원의 벡터를 생성하고 임베딩 벡터에 더하는 식으로 인코딩한다. positional encoding vector 을 생성하는 방식은 짝수번째 차원에서는 $sin(pos/10000^{2i \over d_{model}})$ 을 넣어주고 홀수번째 차원에서는 $cos(pos/10000^{2i \over d_{model}})$ 을 넣는다. (Pos 는 sentence 에서 word 위치, i positional encoding vector 의 element 위치)
Attention
Attention 은 기본적으로 query, set of key-value pairs에서 outputs 으로 가는 함수이고 이 함수는 query 와 key 로 만든 compabitility function 이 value 에 weighted sum 하여 만들어진다. Attention 에는 크게 scaled-dot product attention 과 additive attention 이 있다. additive attention 은 compatibility function 을 하나의 feed-forward network 로 만드는 방식이고 scale-dot product attention 은 이 논문에서 사용한 방식이며 앞으로 설명할 것이다. 논문에 따르면 두 방식 모두 이론적으로 비슷한 복잡도를 내지면 실제로는 후자의 방식이 속도와 공간 복잡도 면에서 유리하다고 한다.
- scaled-dot product attention
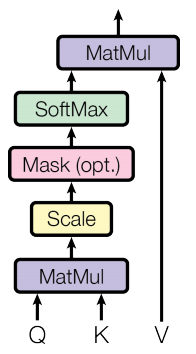
이 때, attention function은 attention(Q,K,V) = $softmax({QK^T \over {\sqrt d_{k}}})V$ 가 된다. 즉, query 와 value 가 비슷해질 수록 대응되는 value 의 element 값이 커진다. 여기서 $d_{k}$ 는 query 와 key 의 dimension 인데 이것의 역수로 스케일해주는 이유는 dot-product 값이 커져서 gradient 가 작아지는 것을 막기 위함이다. 따라서 좀 더 안정적인 gradient 를 생성할 수 있다.
class SelfAttention(nn.Module):
def __init__(self, params):
super(SelfAttention, self).__init__()
self.hidden_dim = params.hidden_dim
self.attention_dim = params.hidden_dim // params.n_head
self.q_w = nn.Linear(self.hidden_dim, self.attention_dim, bias=False)
self.k_w = nn.Linear(self.hidden_dim, self.attention_dim, bias=False)
self.v_w = nn.Linear(self.hidden_dim, self.attention_dim, bias=False)
init_weight(self.q_w)
init_weight(self.k_w)
init_weight(self.v_w)
self.dropout = nn.Dropout(params.dropout)
self.scale_factor = torch.sqrt(torch.FloatTensor([self.attention_dim])).to(params.device)
def forward(self, query, key, value, mask=None):
# query, key, value = [batch size, sentence length, hidden dim]
# create Q, K, V matrices using identical input sentence to calculate self-attention score
q = self.q_w(query)
k = self.k_w(key)
v = self.v_w(value)
# q, k, v = [batch size, sentence length, attention dim]
self_attention = torch.bmm(q, k.permute(0, 2, 1))
self_attention = self_attention / self.scale_factor
# self_attention = [batch size, sentence length, sentence length]
if mask is not None:
self_attention = self_attention.masked_fill(mask, -np.inf)
# normalize self attention score by applying soft max function on each row
attention_score = F.softmax(self_attention, dim=-1)
norm_attention_score = self.dropout(attention_score)
# attention_score = [batch size, sentence length, sentence length]
# compute "weighted" value matrix using self attention score and V matrix
weighted_v = torch.bmm(norm_attention_score, v)
# weighted_v = [batch size, sentence length, attention dim]
return self.dropout(weighted_v), attention_score
- Multi-head attention
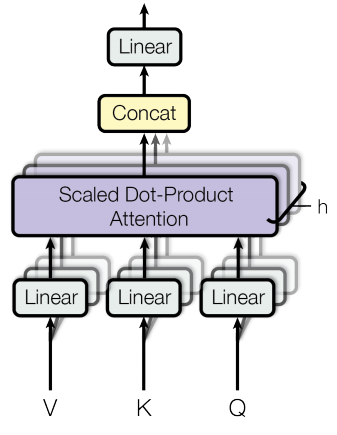
Multi-head attention 에서는 Q, K, V 에 $d_{model}$ 차원의 embedding vector 를 사용하지 말고 num_head 만큼 나누고 각각을 linear projection 한 Q, K, V 에 scaled dot product attention 을 적용하는 방식이다. 즉, Embedding vector 를 X 라 할때, $WqX, WkX, Wv*X$ 로 Query(Q), Key(K), Value(V) 를 구한다. 이렇게 했을 때의 이점은, num_head 만큼의 다른 시각을 가진 query, key, value 를 제공하여 정보를 수집할 수 있어 일종의 앙상블 효과를 노린 것으로 추측된다.
이렇게 만들어진 Attention 함수의 값을 concat 하여 $d_{model}$로 linear projection 한 후, 그 값을 output 으로 사용한다. 즉,
$MultiHead(Q, K, V) = Concat(head_{1}, …, head_{8})W^O \ where \ head_{i}=Attention(QW_{i}^{Q},KW_{i}^{K},VW_{i}^{V})$ 이다.
class MultiHeadAttention(nn.Module):
def __init__(self, params):
super(MultiHeadAttention, self).__init__()
assert params.hidden_dim % params.n_head == 0
self.attentions = nn.ModuleList([SelfAttention(params)
for _ in range(params.n_head)])
self.o_w = nn.Linear(params.hidden_dim, params.hidden_dim, bias=False)
init_weight(self.o_w)
self.dropout = nn.Dropout(params.dropout)
def forward(self, query, key, value, mask=None):
# query, key, value = [batch size, sentence length, hidden dim]
self_attentions = [attention(query, key, value, mask) for attention in self.attentions]
# self_attentions = [batch size, sentence length, attention dim] * num head
weighted_vs = [weighted_v[0] for weighted_v in self_attentions]
attentions = [weighted_v[1] for weighted_v in self_attentions]
weighted_v = torch.cat(weighted_vs, dim=-1)
# weighted_v = [batch size, sentence length, hidden dim]
output = self.dropout(self.o_w(weighted_v))
# output = [batch size, sentence length, hidden dim]
return output, attentions
Position-wise Feed-forward Networks
attention 이 끝나고 $max(0, xW_{1} + b_{1})W_{2}+b_{2}$ 인 feed-forward network 를 추가하여 계산한다. 동일한 구조이지만 다른 parameter 로 각각의 layer 에 구성한다. input 과 output dimention 은 512 로 맞춰주고 FFN 내부의 차원은 2048로 했다.
class PositionWiseFeedForward(nn.Module):
def __init__(self, params):
super(PositionWiseFeedForward, self).__init__()
# nn.Conv1d takes input whose size is (N, C): N is a batch size, C denotes a number of channels
self.conv1 = nn.Conv1d(params.hidden_dim, params.feed_forward_dim, kernel_size=1)
self.conv2 = nn.Conv1d(params.feed_forward_dim, params.hidden_dim, kernel_size=1)
init_weight(self.conv1)
init_weight(self.conv2)
self.dropout = nn.Dropout(params.dropout)
def forward(self, x):
# x = [batch size, sentence length, hidden dim]
# permute x's indices to apply nn.Conv1d on input 'x'
x = x.permute(0, 2, 1) # x = [batch size, hidden dim, sentence length]
output = self.dropout(F.relu(self.conv1(x))) # output = [batch size, feed forward dim, sentence length)
output = self.conv2(output) # output = [batch size, hidden dim, sentence length)
# permute again to restore output's original indices
output = output.permute(0, 2, 1) # output = [batch size, sentence length, hidden dim]
return self.dropout(output)